
Ioncube Loader Extenion allows to run encoded PHP scripts by Ioncube Encoder.
- Ioncube Loader Extension – extension which starts witch PHP process that can read and run encoded files. The extension is free.
- Ioncube Encoder – software that allows encode and obfulscate PHP scripts using license key to description.
This tutorial shows how to install Ioncube Loader Extension.
1. Download Ioncube loader extension.
Go to the http://www.ioncube.com/loaders.php url and locate your proper platofrm version.
If you are not sure what platform (x86 or 64-bit, TS or NTS ) you need, just run phpinfo() and read from „System” and „PHP Extension Build”. For example this entry looks like:
System: Linux athlan-VirtualBox 3.13.0-24-generic #46-Ubuntu SMP Thu Apr 10 19:11:08 UTC 2014 x86_64
PHP Extension Build: API20121212,NTS
I am using 64-bit platform, NTS (non-thread safe).
So copy proper link and call:
wget http://downloads3.ioncube.com/loader_downloads/ioncube_loaders_lin_x86-64.tar.gz
Extract the package
tar xvfz ioncube_loaders_lin_x86-64.tar.gz
athlan@athlan-VirtualBox:~/tmp/ioncube$ ls -1 ioncube_loader_lin_4.1.so ioncube_loader_lin_4.2.so ioncube_loader_lin_4.3.so ioncube_loader_lin_4.3_ts.so ioncube_loader_lin_4.4.so ioncube_loader_lin_4.4_ts.so ioncube_loader_lin_5.0.so ioncube_loader_lin_5.0_ts.so ioncube_loader_lin_5.1.so ioncube_loader_lin_5.1_ts.so ioncube_loader_lin_5.2.so ioncube_loader_lin_5.2_ts.so ioncube_loader_lin_5.3.so ioncube_loader_lin_5.3_ts.so ioncube_loader_lin_5.4.so ioncube_loader_lin_5.4_ts.so ioncube_loader_lin_5.5.so ioncube_loader_lin_5.5_ts.so ioncube_loader_lin_5.6.so ioncube_loader_lin_5.6_ts.so LICENSE.txt loader-wizard.php README.txt USER-GUIDE.txt
2. Copy extension to PHP extension dir
Locate your extenion dir:
athlan@athlan-VirtualBox:~/tmp/ioncube$ php -i | grep extension_dir
extension_dir => /usr/lib/php5/20121212 => /usr/lib/php5/20121212
Copy here your proper loader, in my case:
cp ./ioncube_loader_lin_5.5.so /usr/lib/php5/20121212
3. Add extension to php.ini file
You must add Ioncube Loader to php.ini file pointing proper file:
zend_extension=ioncube_loader_lin_5.5.so
Make sure that extension is the first loaded extension for PHP, because the error will appear:
PHP Fatal error: Unable to start ionCube Loader module in Unknown on line 0
In my Ubuntu the extensions directory are under: /etc/php5/mods-available directory – one per extension. So define ioncube.ini file. In php+apache2 for ubuntu there are configuratios groupped by environment, one is apache2, so I make symbolic link to include my .ini file:
ln -s .etc/php5/mods-available/ioncube.ini /etc/php5/apache2/conf.d/01-ioncube.ini
I named my file by prefix 01- to make sure that it will be the first included extension.
4. Check configuration
Make file with phpinfo() and check if Ioncube is loaded under „Additional Modules” and „with the ionCube PHP Loader (enabled) + Intrusion Protection from ioncube24.com (unconfigured) v5.0.11, Copyright (c) 2002-2015, by ionCube Ltd.”:
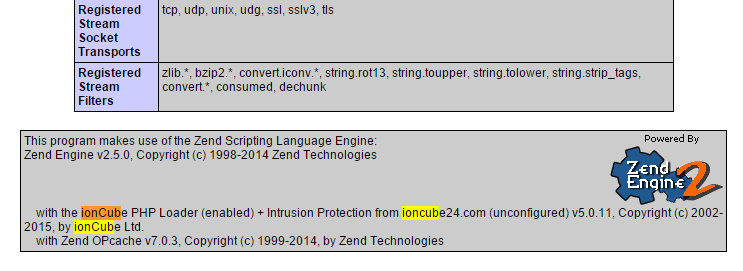

Done!
Known issues:
Apache hangs while start
The apache2 instance did not start within 20 seconds. Please read the log files to discover problems
Probably you have not proper version of your extension included (TS or NTS). Please verify that comparing to your phpinfo() „System” and „PHP Extension Build”.
Invalid extension definition
[Sat Jul 11 15:44:24 2015] [warn-phpd] The ionCube Loader is a Zend-Engine extension and not a module (pid 3038)
[Sat Jul 11 15:44:24 2015] [warn-phpd] Please specify the Loader using 'zend_extension’ in php.ini (pid 3038)
You have included Ioncube by extension= while zend_extension= should be used.
Ioncube Loader is loaded after another extensions
PHP Fatal error: [ionCube Loader]
The Loader must appear as the first entry in the php.ini file in Unknown on line 0
You have to specify zend_extension directive in php.ini as a first extension loaded. To make sure, just place it as a first line.
